A 2026 Field Guide to Visual Document Processing

If you've shopped for an OCR model recently, you already know the problem: every vendor claims state-of-the-art accuracy, every benchmark uses a different dataset, and "VLMs can do OCR" is technically true of a dozen models. As a buying criterion, it's nearly useless.
We built JSL Vision and wanted to know exactly where it stands against the full field. This series documents that comparison: 20+ open-source and closed-source models, three production tasks, one consistent methodology.
The short answer is that different VLMs are good at different tasks, and the gap can be dramatic. The model that wins flat-text OCR is not the one that wins schema-constrained JSON extraction. Several frontier APIs that perform well on general benchmarks are essentially unusable for grounded OCR. And the model that ranked #1 on JSON finished near the bottom on flat-text transcription.
Here's what we found, and why it matters for production use in regulated environments.
With this benchmark, we are releasing three production models, each purpose-built for a different document task:
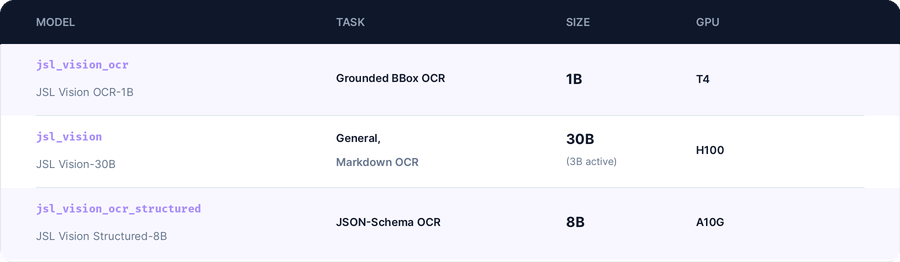
Three tasks, three production realities

A live sampling of the three OCR tasks JSL Vision handles in production: bounding-box grounding, plain-text reading, and schema-conformant JSON extraction. 21 documents, cycled equally.
Try it live: All three models are available in 11 interactive demos at the JSL Vision Workshop — de-identification, radiology RAG, KYC, invoice processing, ECG analysis, and more. Or watch the 1-hour workshop walkthrough on YouTube.
Every document pipeline ultimately does one (or more) of three things:
1. Grounded (BBox) OCR. Read the text and locate it precisely on the page. This is the foundation for de-identification, field extraction, redaction, and compliance audits. If your pipeline ever needs to provide evidence to support the findings present in text, you need bounding boxes.
2. Image → Markdown OCR. Just give me clean text in natural reading order. This is what RAG pipelines, search indexing, clinical summarization, and downstream LLM reasoning consume. Coordinates are wasted; markdown is plenty.
3. JSON-Schema OCR. Give me a structured object that conforms to this schema. EHR ingestion, claims automation, clinical trial data capture, anywhere a downstream system expects specific fields in specific shapes, this is the task.
The same model can excel at one and fail at another. A model that aces flat OCR can hallucinate coordinates. A model that's great at JSON extraction can be a mediocre transcriber. That's why the series breaks the benchmark up by task.
How JSL Vision performs across the series
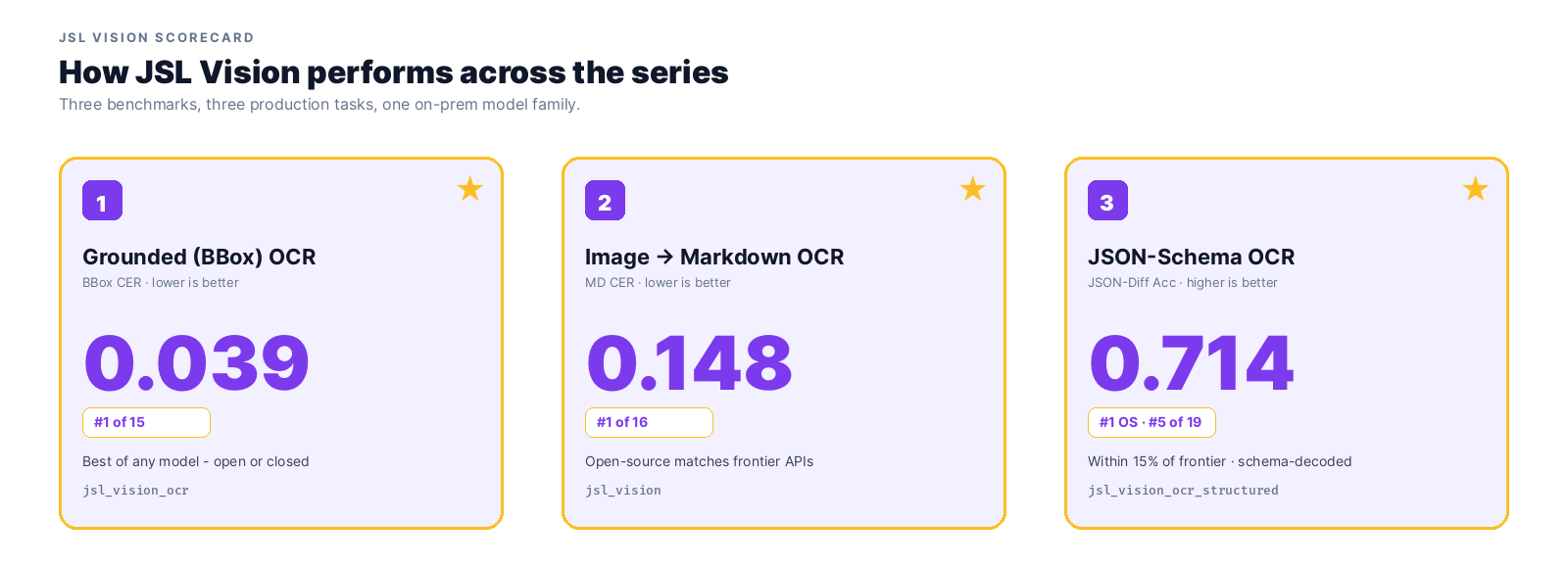
Across all three tasks, JSL Vision leads the leaderboard:
- Grounded OCR:
jsl_vision_ocris #1 of 15 at 0.039 BBox CER, better than every closed-source frontier model, including Gemini 2.5 Pro (T4) - Markdown OCR:
jsl_visionis #1 of 16 at 0.148 CER, beating Grok-4, Gemini 2.5 Pro, and the entire Claude line (H100) - JSON-Schema OCR:
jsl_vision_ocr_structuredis #1 on-prem (#5 of 23 overall) at 0.730 json-diff accuracy, within 18% of frontier closed-source while guaranteeing valid JSON via schema-aware decoding (A10G)
All numbers reproducible. All models run on your own infrastructure. No data leaves your environment.
Why this matters for healthcare and regulated industries
In regulated workflows, "best benchmark score" isn't the optimization function. What actually matters: whether JSON outputs are guaranteed valid (invalid JSON crashes downstream systems; frontier APIs mostly comply, some open-source models guarantee it structurally), whether outputs are deterministic (same input, same output, every run, required for audit and compliance), whether data stays on your infrastructure (HIPAA, GDPR, SOC 2 mean you can't use a third-party API without a data-sharing agreement), and what the cost model actually looks like (a single H100 at $2.50/hour is fundamentally different from per-token API billing: 2–13× cheaper than comparable closed-source models).
JSL Vision Structured-8B beats Claude Sonnet 4.5 outright (on-prem, on an A10G, at a fraction of the API cost). The only models ahead of it are GPT-5.2, Gemini Flash, Gemini Pro, and Claude Opus. For regulated industries, an 18% accuracy gap to the absolute frontier rarely justifies the operational cost: data-sharing agreements, audit trails, latency tails, and the 3 AM wakeup when a vendor's API has an outage.
The series
Part 1: Grounded (BBox) OCR on FUNSD
The best grounded OCR, open- or closed-source. JSL Vision OCR (jsl_vision_ocr) is #1 overall at 0.039 CER, beating every closed-source model including Gemini 2.5 Pro. Most CS VLMs (GPT-5.2, Grok-4, Claude Opus) hallucinate coordinates. 6 popular OS models can't do BBox at all (including Chandra OCR 2).
Part 2: Image → Markdown OCR on FUNSD
Self-hosted matches frontier APIs. JSL Vision (jsl_vision) is #1 overall at 0.148 CER. The gap between the best self-hosted model and the best closed-source API is < 1% absolute CER: there's no accuracy reason left to route your documents to a third-party cloud.
Part 3: Schema-Constrained JSON OCR on OmniOCR Where best at OCR ≠ best at schema-following. GPT-5.2 wins outright at 0.888 json-diff accuracy despite ranking 14th on flat OCR. JSL Vision Structured-8B is #1 self-hosted at 0.730 with 100% guaranteed-valid JSON via schema-aware decoding, deployable on a single A10G.
On the roadmap
Next in the pipeline: medical de-identification on clinical notes with JSL's specialized DEID models, long-form document understanding on OmniDocBench, medical visual QA on OmniMedVQA, fine-grained OCR primitives via OCRBench, chart understanding on CharXiv, and domain-specific fine-tunes for handwriting, lab reports, and insurance forms.
If you work on document AI in healthcare, life sciences, or any other regulated industry, read on. The next decade of enterprise AI runs on documents, and the gap between VLMs that demo well and VLMs that run in production is exactly what this series measures.
JSL Vision is the only on-prem model family that wins all three production OCR benchmarks, at a fraction of the cost of frontier APIs, with deterministic outputs, on hardware you control.
Running OCR in a regulated environment? Schedule a demo and we'll walk through how JSL Vision fits your specific workflow.